№ P2
FRAMEWORK OVERVIEW框架概览
Two stages, one pipeline: preserve then detect. 两个阶段,一个流程:先保留再检测。
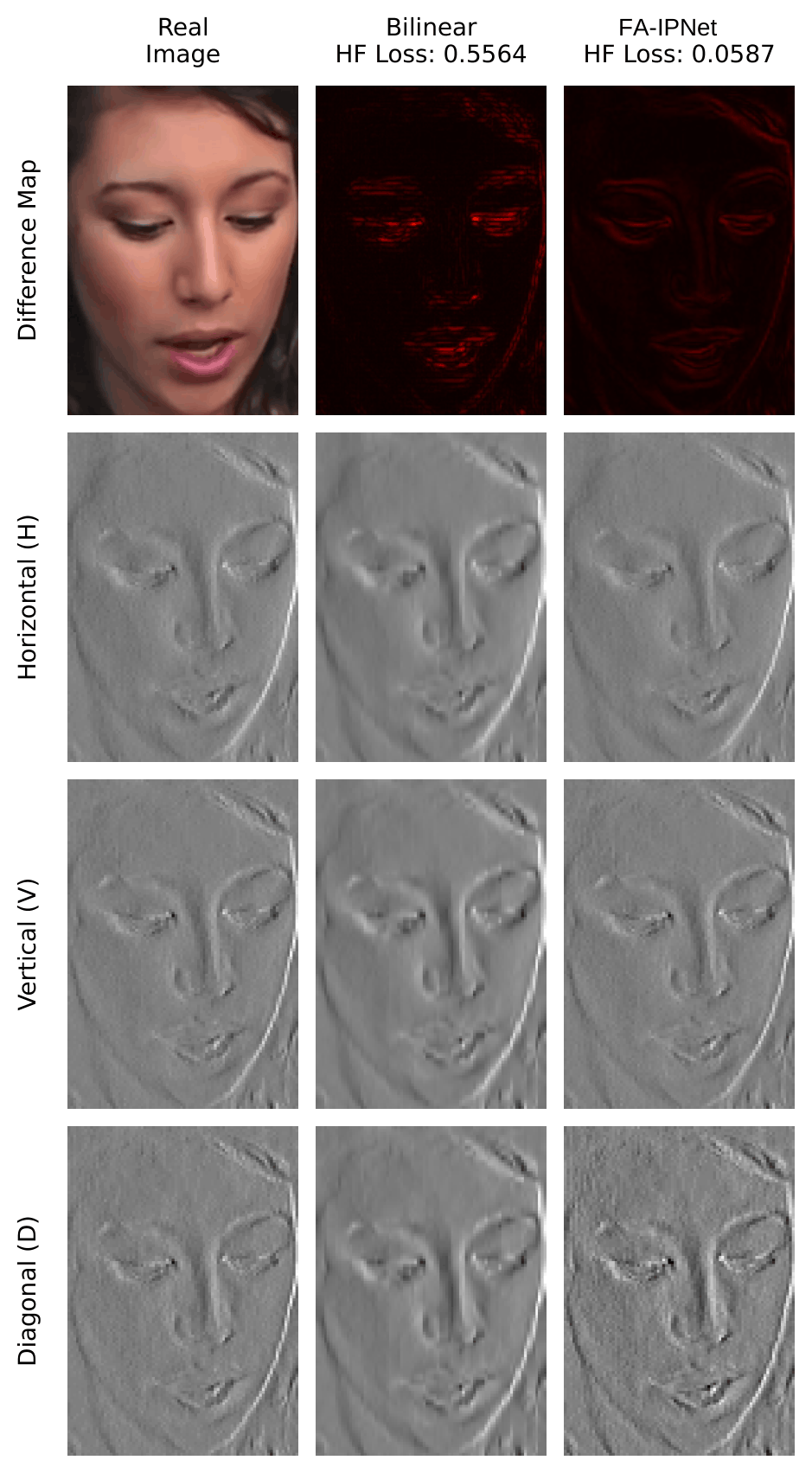
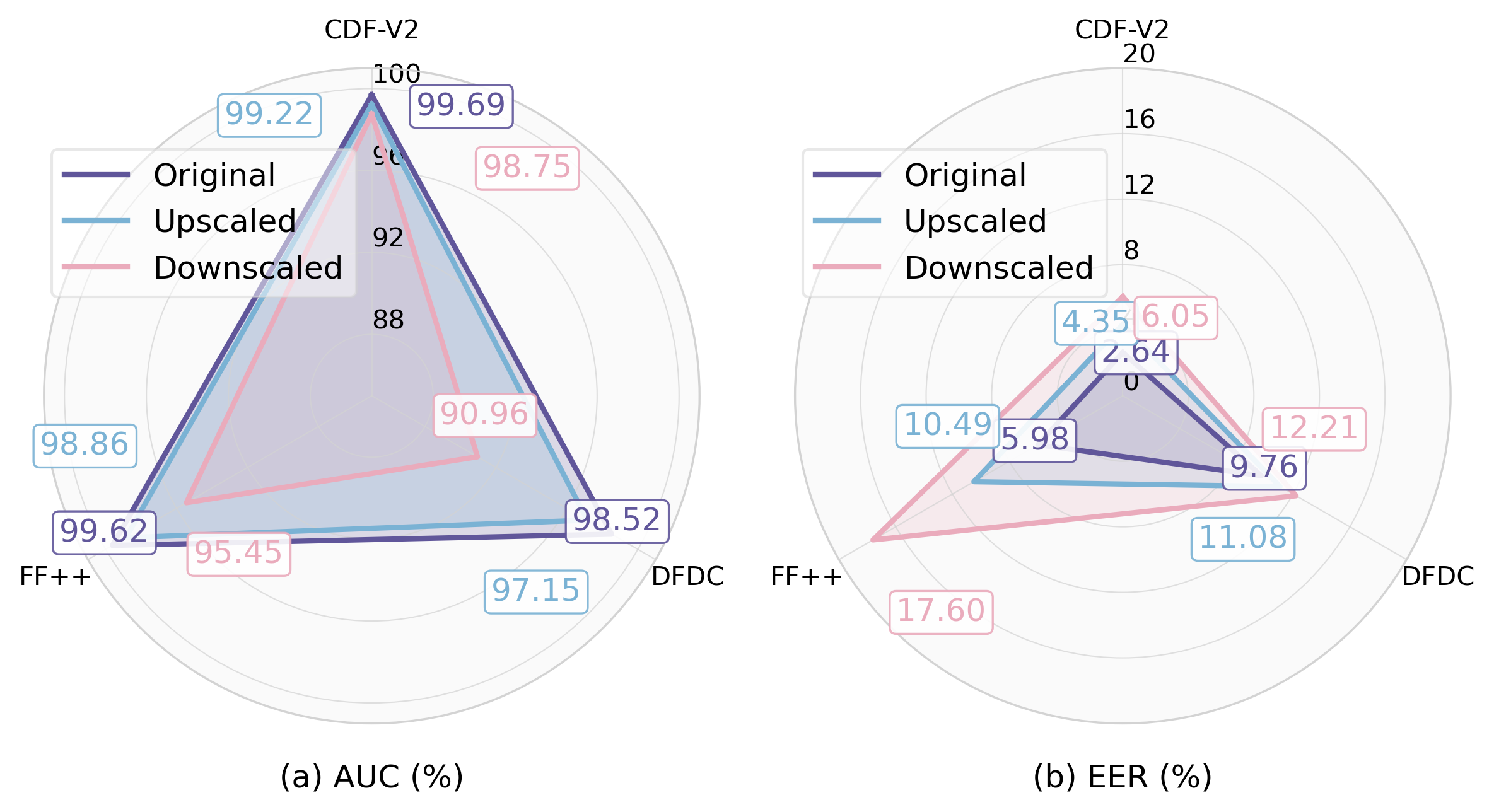
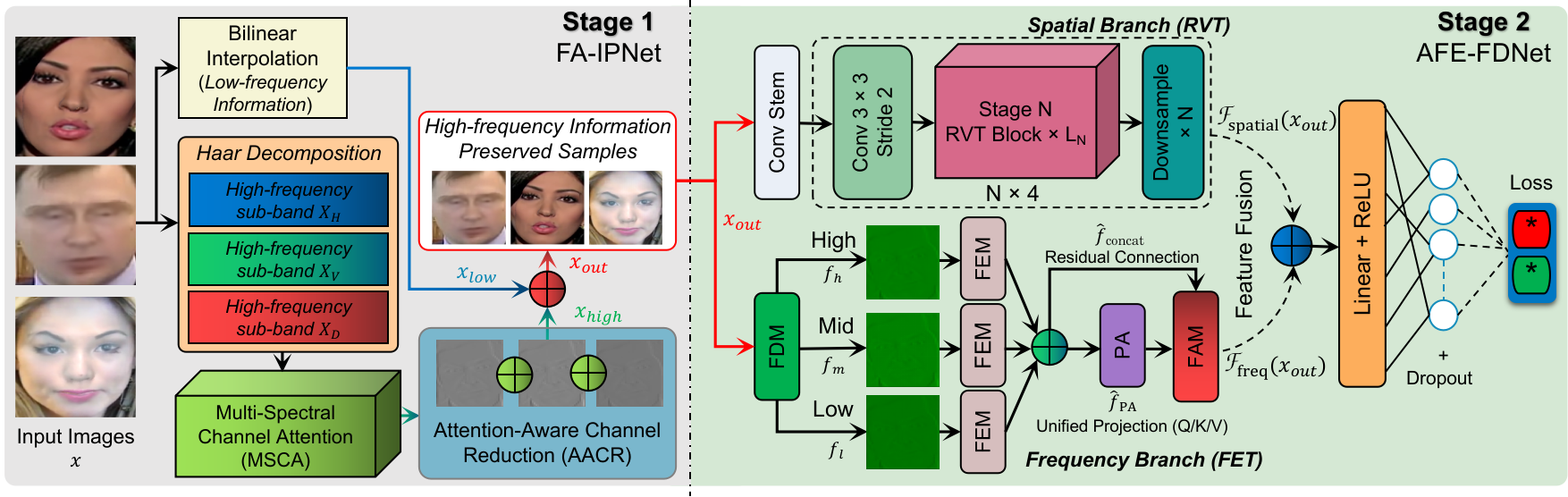 Fig. 1 — Overview of the proposed two-stage deepfake defense framework. Stage 1 (FA-IPNet) preserves forensic HF cues. Stage 2 (AFE-FDNet) extracts complementary evidence through spatial (RVT) and frequency (FET) branches.
图1 — 所提出的两阶段深度伪造防御框架概览。阶段1(FA-IPNet)保留取证高频线索。阶段2(AFE-FDNet)通过空间(RVT)和频域(FET)分支提取互补证据。
Fig. 1 — Overview of the proposed two-stage deepfake defense framework. Stage 1 (FA-IPNet) preserves forensic HF cues. Stage 2 (AFE-FDNet) extracts complementary evidence through spatial (RVT) and frequency (FET) branches.
图1 — 所提出的两阶段深度伪造防御框架概览。阶段1(FA-IPNet)保留取证高频线索。阶段2(AFE-FDNet)通过空间(RVT)和频域(FET)分支提取互补证据。
© 2026 IEEE. Figure reproduced with permission from IEEE Transactions on Consumer Electronics. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses. © 2026 IEEE。经IEEE Transactions on Consumer Electronics许可转载。允许个人使用此材料。所有其他用途必须获得IEEE许可。