№ P2
FRAMEWORK OVERVIEW框架概览
Spatial vision meets spectral language: a dual-branch transformer. 空间视觉与频谱语言相遇:双分支Transformer。
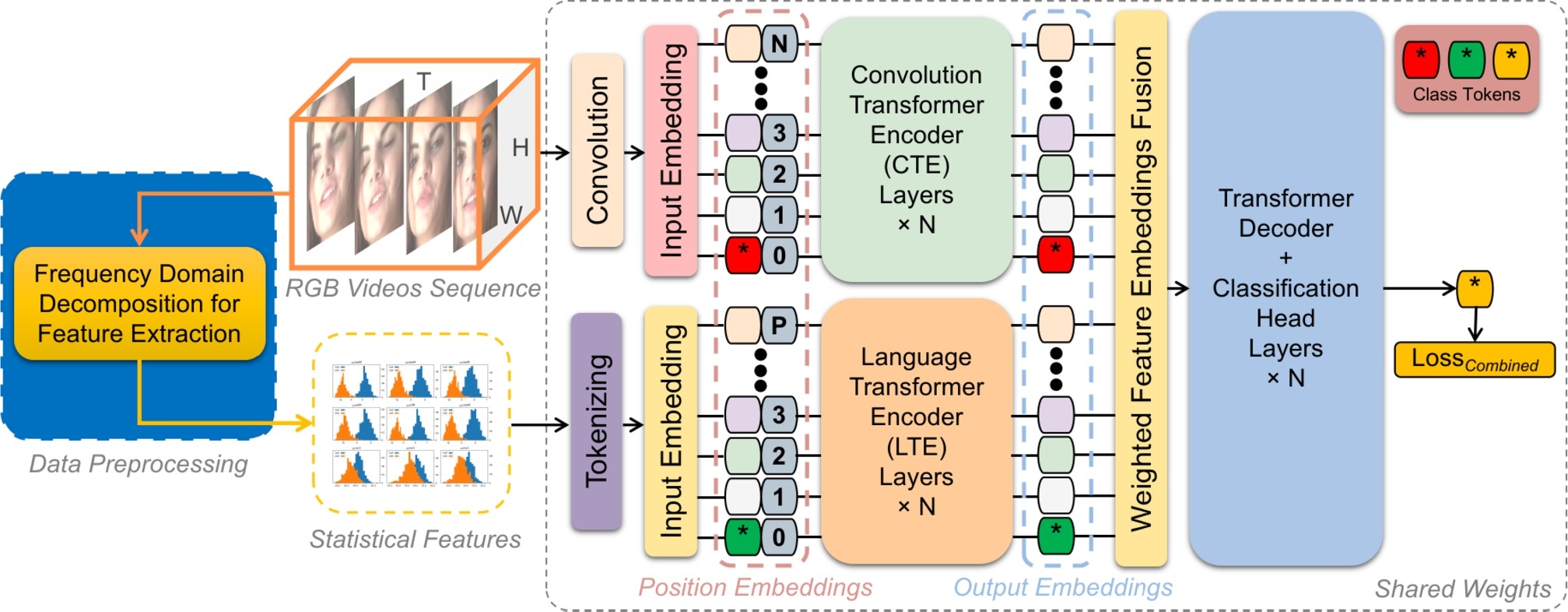 Fig. 1 — Overview of the SVFT model pipeline. The Convolutional Transformer Encoder (CTE) processes RGB video frames for spatial cues, while the Language Transformer Encoder (LTE) processes spectral statistical features for frequency cues. A weighted fusion layer and common cross-attention decoder enable joint analysis. © 2024 Elsevier.
图1 — SVFT模型流程概览。卷积Transformer编码器(CTE)处理RGB视频帧以提取空间线索,语言Transformer编码器(LTE)处理频谱统计特征以提取频域线索。加权融合层和公共交叉注意力解码器实现联合分析。© 2024 Elsevier。
Fig. 1 — Overview of the SVFT model pipeline. The Convolutional Transformer Encoder (CTE) processes RGB video frames for spatial cues, while the Language Transformer Encoder (LTE) processes spectral statistical features for frequency cues. A weighted fusion layer and common cross-attention decoder enable joint analysis. © 2024 Elsevier.
图1 — SVFT模型流程概览。卷积Transformer编码器(CTE)处理RGB视频帧以提取空间线索,语言Transformer编码器(LTE)处理频谱统计特征以提取频域线索。加权融合层和公共交叉注意力解码器实现联合分析。© 2024 Elsevier。
© 2024 THE AUTHORS. Published by Elsevier BV on behalf of Faculty of Engineering, Alexandria University. This is an open access article under the CC BY-NC-ND license. © 2024 作者。由Elsevier BV代表亚历山大大学工程学院出版。本文根据CC BY-NC-ND许可进行开放获取。