№ P2
FRAMEWORK OVERVIEW框架概览
Two stages, multiple color spaces, one goal. 两个阶段,多种色彩空间,一个目标。
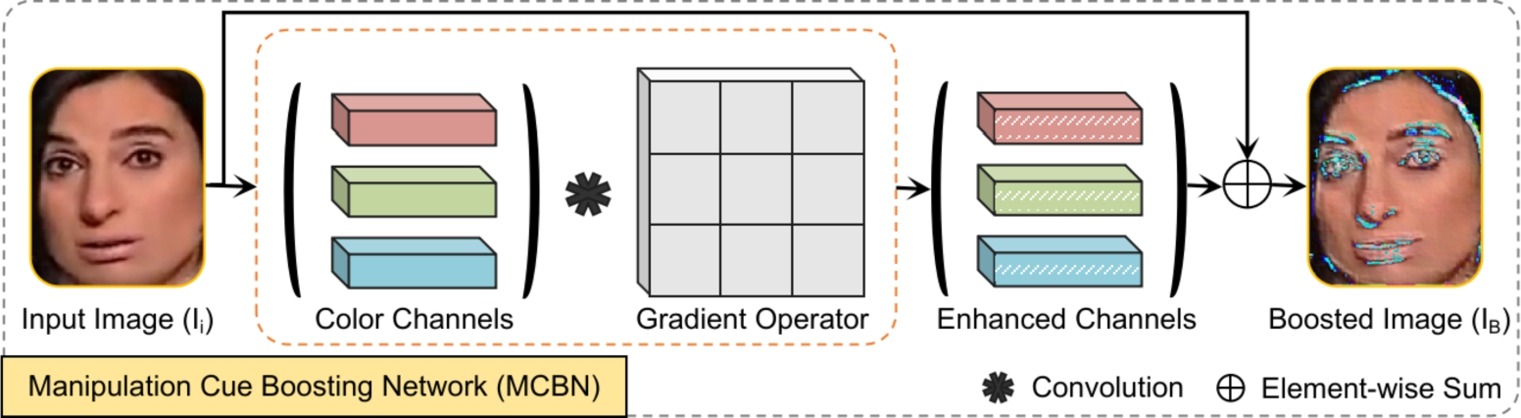
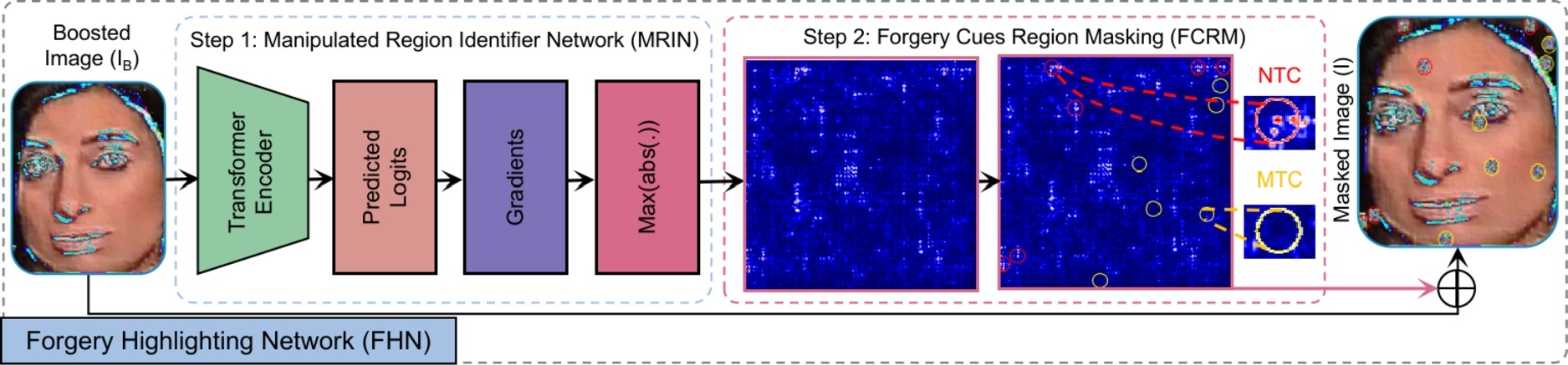
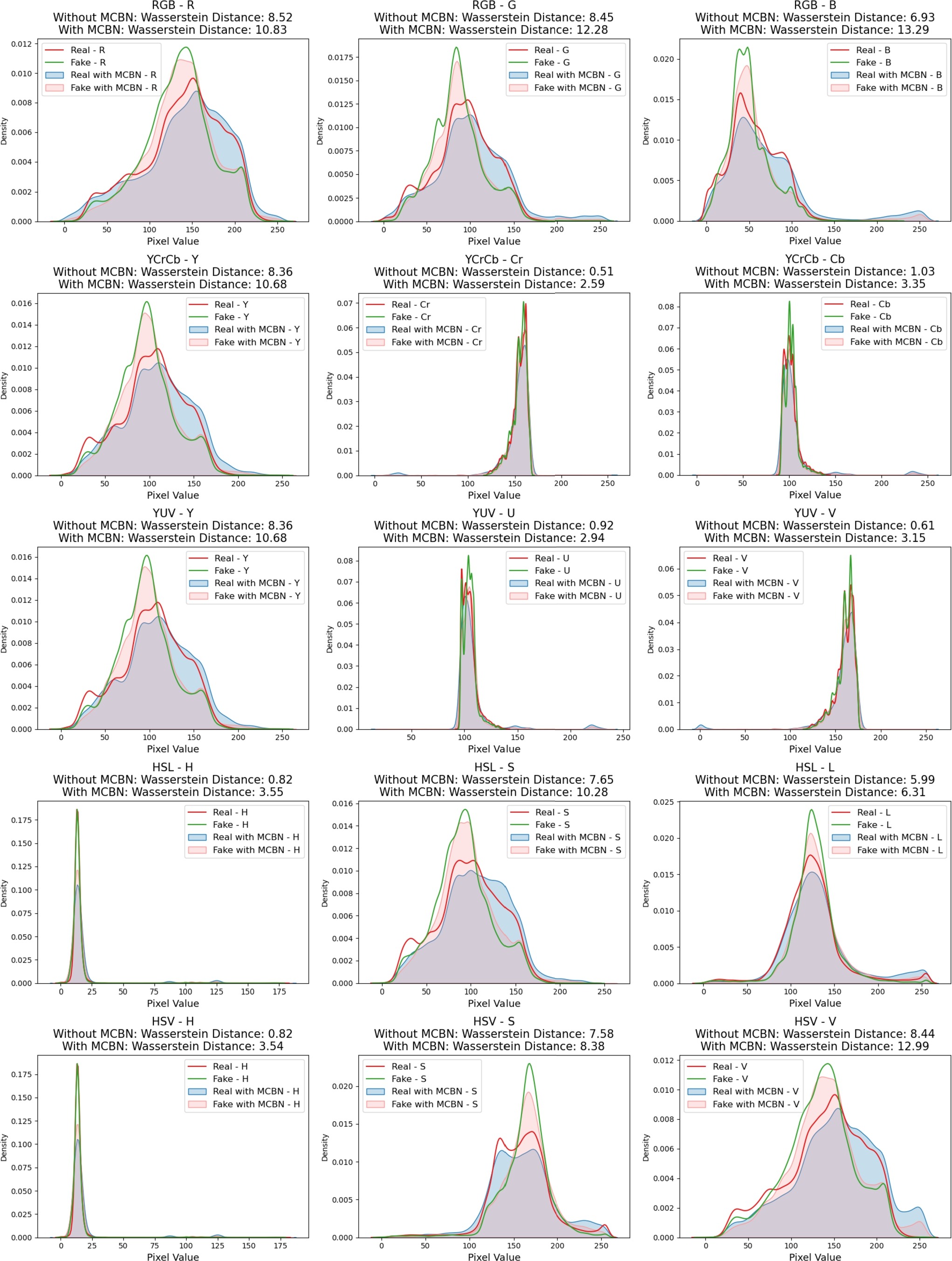
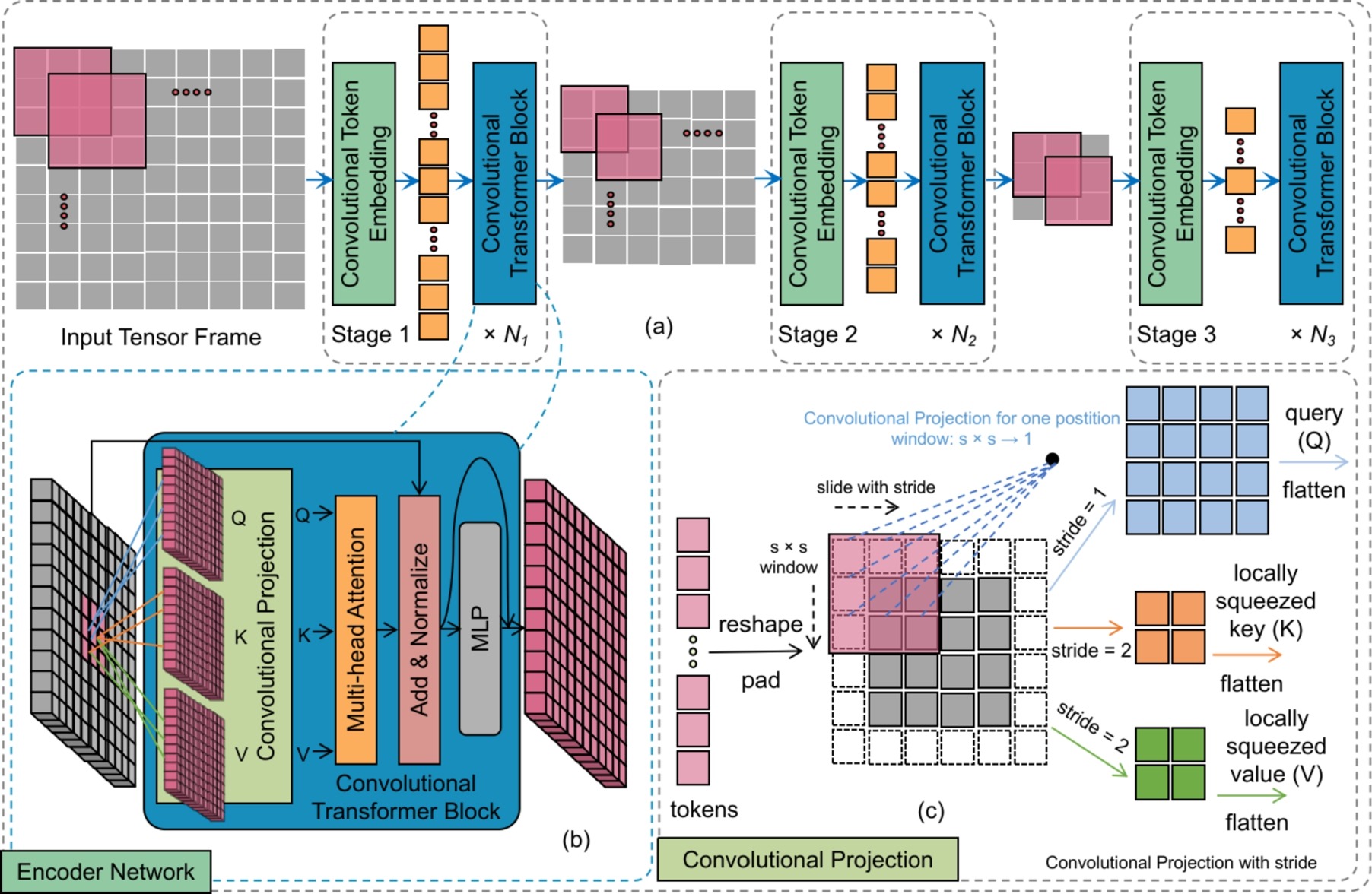
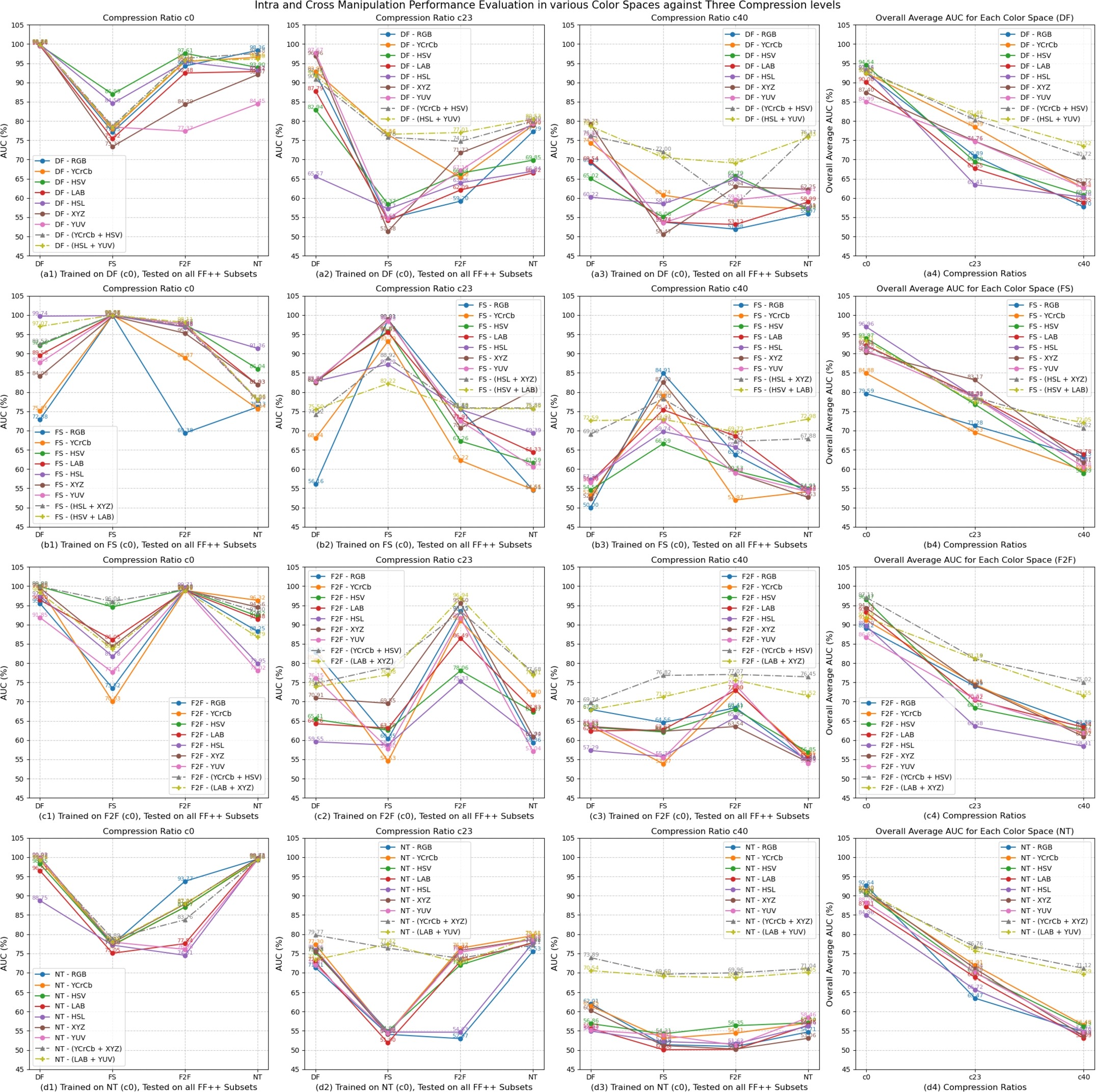
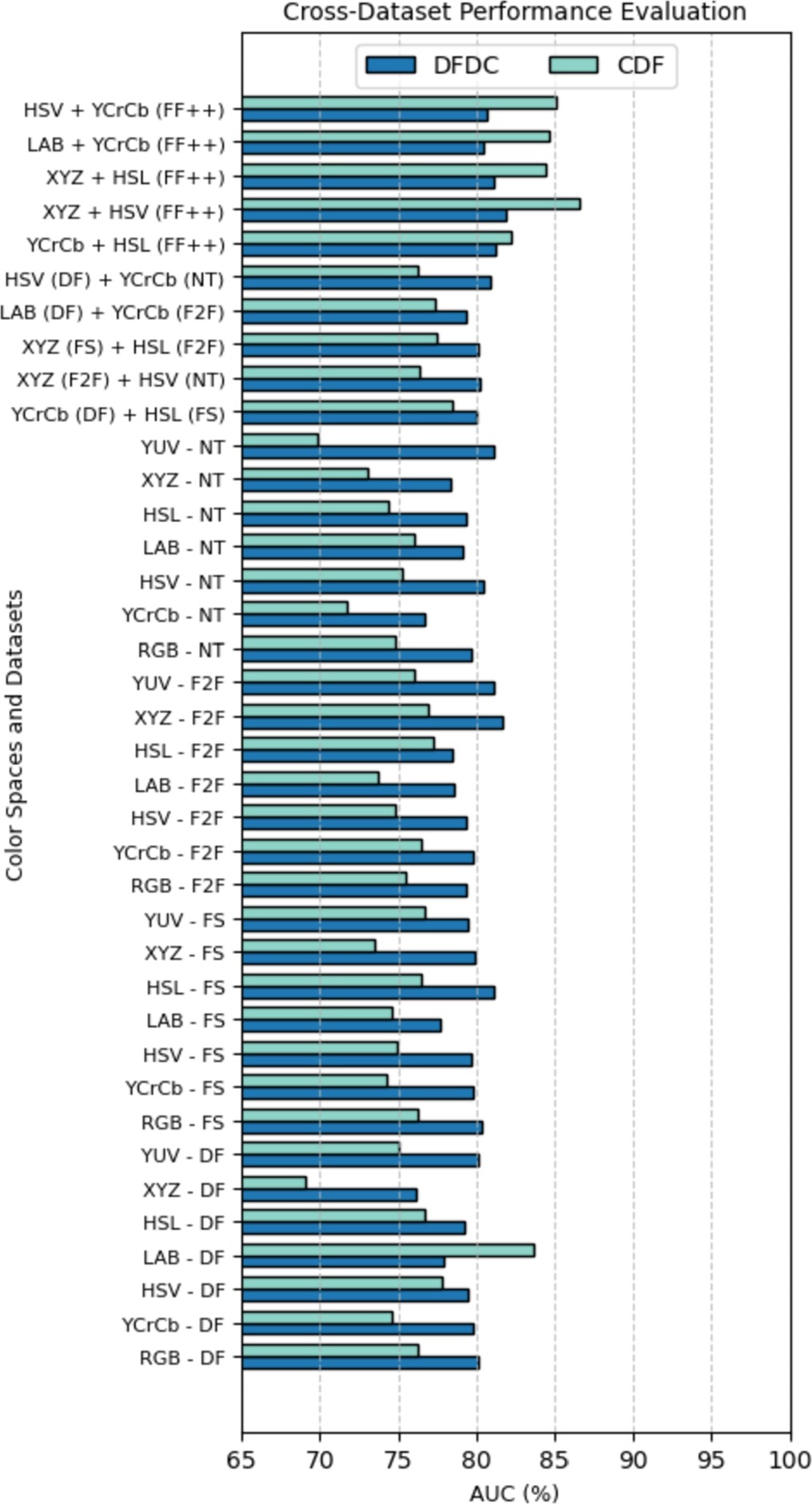
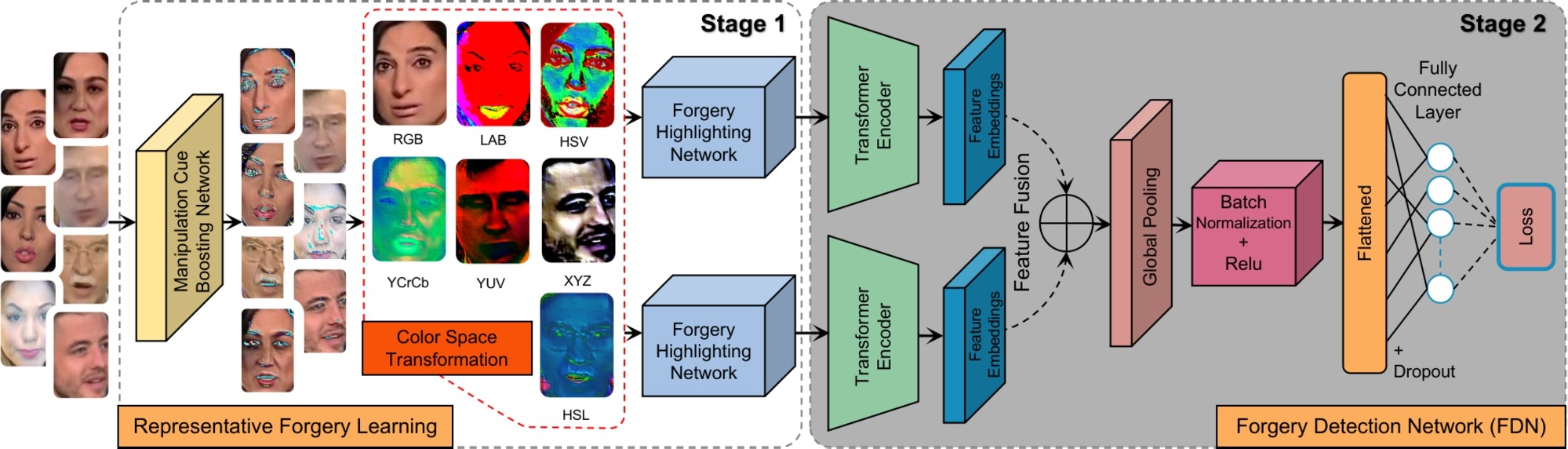 Fig. 1 — Overall framework: representative forgery learning (Stage 1) + color spaces-based Forgery Detection Network (Stage 2). © 2024 Elsevier.
图1 — 整体框架:代表性伪造学习(第一阶段)+ 基于色彩空间的伪造检测网络(第二阶段)。© 2024 Elsevier。
Fig. 1 — Overall framework: representative forgery learning (Stage 1) + color spaces-based Forgery Detection Network (Stage 2). © 2024 Elsevier.
图1 — 整体框架:代表性伪造学习(第一阶段)+ 基于色彩空间的伪造检测网络(第二阶段)。© 2024 Elsevier。
© 2024 Elsevier Inc. Figure reproduced with permission from Digital Signal Processing. Personal use of this material is permitted. © 2024 Elsevier Inc。经Digital Signal Processing许可转载。允许个人使用此材料。