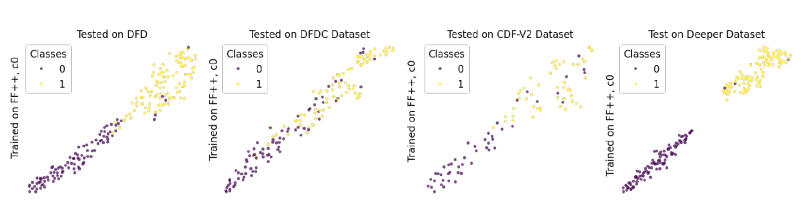
№ P2
FRAMEWORK OVERVIEW框架概览
Two levels, one pipeline: model then analyze. 两个层次,一个流程:先建模再分析。
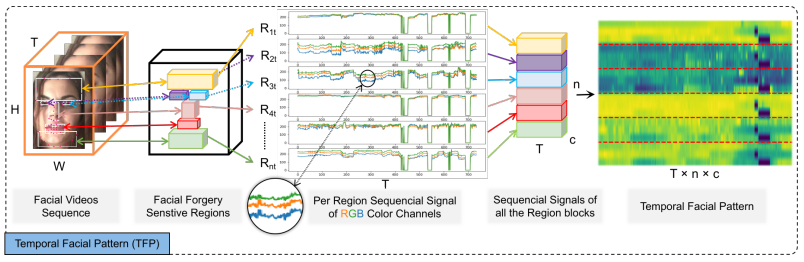
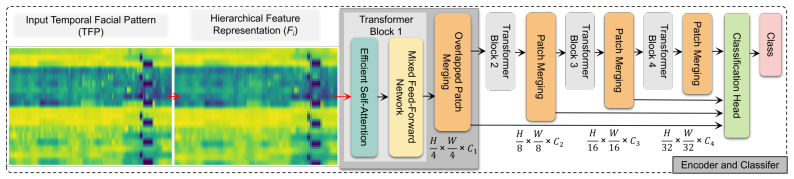
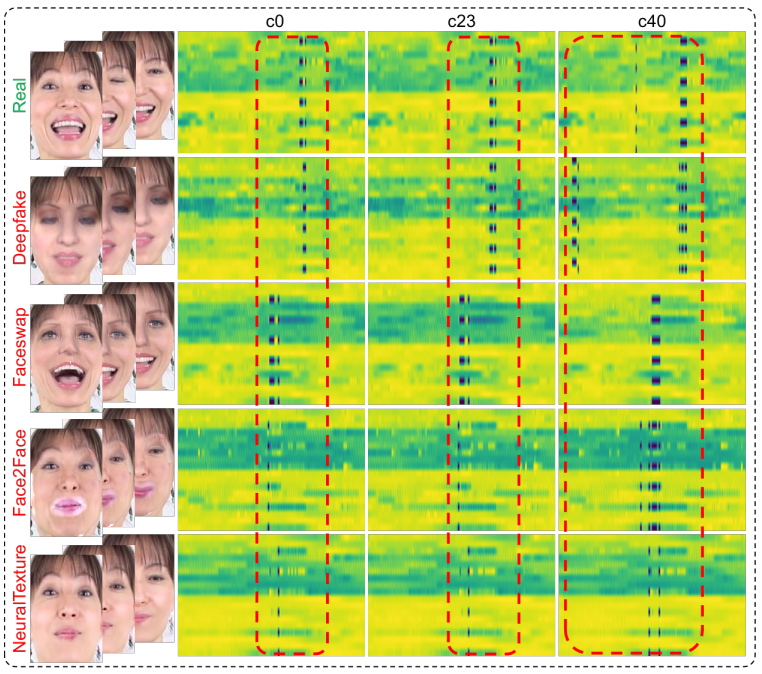
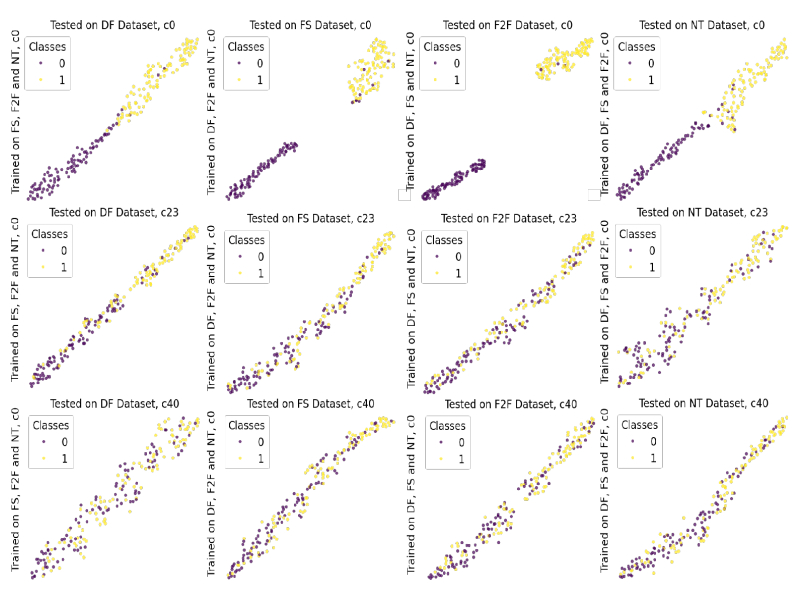
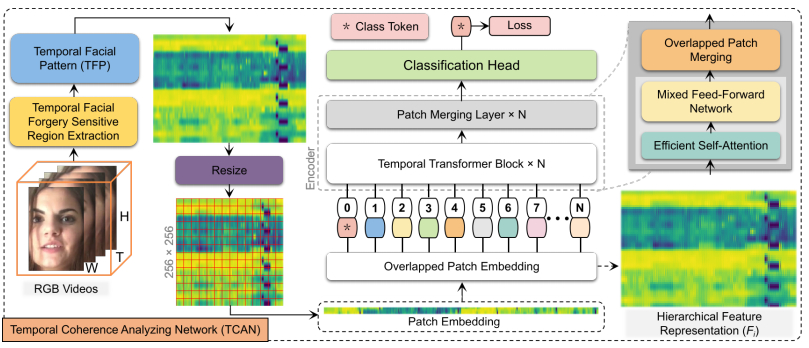 Fig. 1 — An illustration of the proposed deepfake video detection framework based on temporal facial pattern (TFP) and temporal coherence analyzing network (TCAN). TCAN has two main components: a hierarchical transformer encoder for feature extraction and a classification head for feature fusion and output.
图1 — 所提出的基于时序面部模式(TFP)和时序一致性分析网络(TCAN)的深度伪造视频检测框架示意图。TCAN有两个主要组件:用于特征提取的分层Transformer编码器和用于特征融合与输出的分类头。
Fig. 1 — An illustration of the proposed deepfake video detection framework based on temporal facial pattern (TFP) and temporal coherence analyzing network (TCAN). TCAN has two main components: a hierarchical transformer encoder for feature extraction and a classification head for feature fusion and output.
图1 — 所提出的基于时序面部模式(TFP)和时序一致性分析网络(TCAN)的深度伪造视频检测框架示意图。TCAN有两个主要组件:用于特征提取的分层Transformer编码器和用于特征融合与输出的分类头。
© 2024 AIMS Press. Figure reproduced with permission from Electronic Research Archive. This is an open access article distributed under the terms of the Creative Commons Attribution License. © 2024 AIMS Press。经Electronic Research Archive许可转载。本文根据知识共享署名许可条款以开放获取方式分发。