№ P2
FRAMEWORK OVERVIEW框架概览
From color channels to spectral evidence: a lightweight pipeline. 从颜色通道到频谱证据:一个轻量级流程。
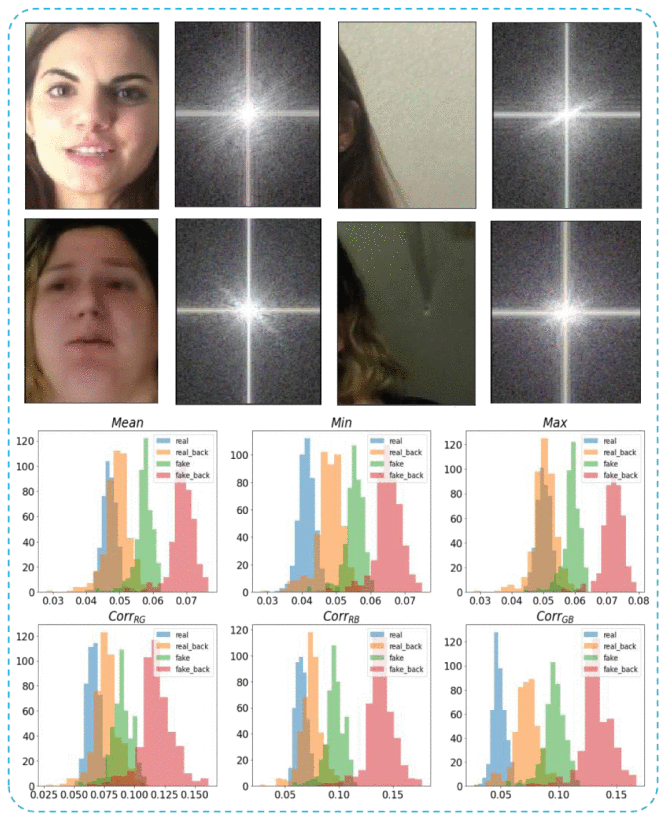
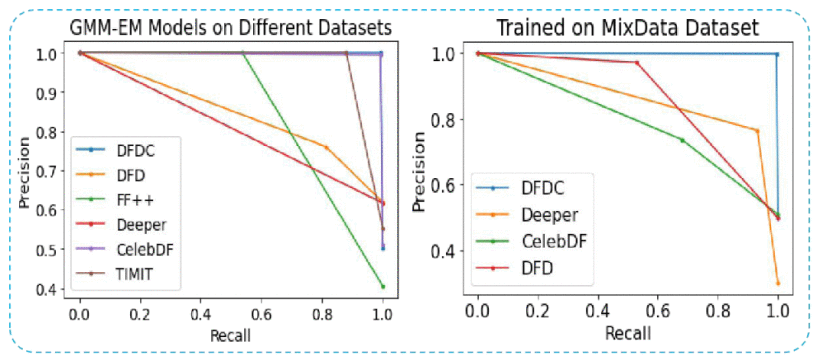
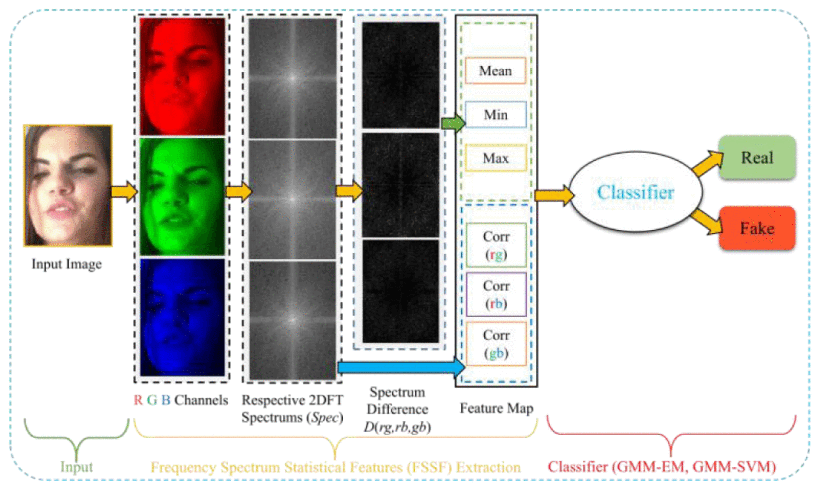 Fig. 1 — Overview of the proposed deepfake detection pipeline. Input frames are decomposed into RGB channels; 2D DFT amplitude spectra are computed; cross-channel spectrum differences are analyzed; and statistical features (Mean, Min, Max, Corr_RG, Corr_RB, Corr_GB) are fed into GMM-EM or SVM classifiers.
图1 — 所提出的深度伪造检测流程概览。输入帧被分解为RGB通道;计算二维DFT幅度频谱;分析跨通道频谱差异;并将统计特征(均值、最小值、最大值、Corr_RG、Corr_RB、Corr_GB)输入GMM-EM或SVM分类器。
Fig. 1 — Overview of the proposed deepfake detection pipeline. Input frames are decomposed into RGB channels; 2D DFT amplitude spectra are computed; cross-channel spectrum differences are analyzed; and statistical features (Mean, Min, Max, Corr_RG, Corr_RB, Corr_GB) are fed into GMM-EM or SVM classifiers.
图1 — 所提出的深度伪造检测流程概览。输入帧被分解为RGB通道;计算二维DFT幅度频谱;分析跨通道频谱差异;并将统计特征(均值、最小值、最大值、Corr_RG、Corr_RB、Corr_GB)输入GMM-EM或SVM分类器。
© 2023 IEEE. Figure reproduced with permission from 2023 11th International Workshop on Biometrics and Forensics (IWBF). Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses. © 2023 IEEE。经2023第11届生物识别与取证国际研讨会(IWBF)许可转载。允许个人使用此材料。所有其他用途必须获得IEEE许可。